As agents write more and more of the code, our job has shifted towards ownership: less time spent writing, more reviewing diffs, catching architectural gaps, ensuring quality doesn't slip.
I'd like to walk you through my daily-driver test coverage tooling: how I keep the feedback loop tight when agents are doing the heavy lifting.
This was a hot topic at the amazing RubyConf Austria earlier this year:

Hans Schnedlitz, Armin Ronacher, Chad Fowler, Obie Fernandez and José Valim discussing the future of coding with AI.
But does the loop work?
In my previous post "Teaching Claude Code to Test What Breaks" I ran a contrived experiment to check whether a test coverage harness with undercover will have any effects on the code produced by Opus and Sonnet models. Agents were prompted to implement a sample but complex-enough CLI app. All were asked to supply tests, but only half followed the workflow of writing tests and reviewing their coverage prescribed by the /coverage skill.
TLDR: the feedback loop produced fewer LOC overall, overly defensive and redundant blocks were removed (good) and there were fewer and more surface level bugs. Check out the original writeup for more details.
Of course there is a cost: more time, tokens and turns. I think it's a worthy investment, because Claude Code, being trained to complete the given task, may as well say "good enough" to tests with < 75% branch coverage. In fact, I've just finished iterating on a PR stack today at work, where a similar feedback loop was employed in a GPT 5.5 pi agent.
These four approaches build on each other: from running a command yourself (try it when reviewing your next PR!), to guiding your agents running the loop itself and enforcing coverage across your whole team with a GitHub Check.
1. Pre-commit coverage check
The baseline undercover local check: do any methods in my feature branch diff require additional tests?
undercover --compare origin/main --format json
undercover: ✅ No coverage is missing in latest changes
Undercover finished in 0.0974s
A failure with 1 warning, using a less verbose and agent-friendly option: --format json, recently added in undercover v0.8.5:
undercover -c master --simplecov coverage/coverage.json --format json
{
"warnings": [
{
"node": "email_subject",
"type": "instance method",
"file": "app/mailers/user_mailer.rb",
"first_line": 12,
"last_line": 20,
"coverage": 0.8,
"uncovered_lines": [
16
],
"uncovered_branches": [
{
"line": 16,
"block": 0,
"branch": 1,
"description": "then"
}
]
}
],
"summary": {
"total_warnings": 1,
"files_affected": 1
}
}
Your coding agent will know what to do with this data.
2. AGENTS.md
A step further would be to instruct our coding buddy to check for coverage on their own, when necessary, without intervention and get back to us with results that meet our standards.
Here's a compact AGENTS.md snippet that I use daily. Assumes you have SimpleCov and Undercover set up.
# AGENTS.md
Run `undercover -c origin/main --format json` after a successful test run to check test coverage of your changes.
Create new or update existing tests if any methods were flagged by `undercover`, until sufficient coverage is reported.
In my experience agents based on newer models figure out on their own how to filter specs and run just the right subset of files to meet the undercover guard.
3. Claude Code /coverage skill
The above feedback loop is available to the /coverage skill, which has some more capabilities. Besides making the agent loop between implementation and testing reviews, it will run coverage and tests more selectively (via --include-files) and debate and suggest skipping certain tests via :nocov:.
A few ways you can run it:
/coverage set up coverage for this Rails app
Adds simplecov and undercover to the Gemfile, wires SimpleCov::Formatter::Undercover and creates .undercover with -c origin/main. Local agent permissions will be updated so the loop runs without prompts too.
/coverage keep changes covered as we go
Run undercover after each change with the correct args and fills gaps.
/coverage check the coverage feedback on this PR and fix it
Pulls the coverage check's annotations, adds the missing tests and verifies locally.
Go check out the undercover-claude readme for setup instructions and more details.
4. PR feedback with UndercoverCI
Finally, if you work in a team, I would recommend having a fast feedback loop like one of the above, as well as a CI step that reviews every pull requests and enforces a common quality bar for everyone.
One way to achieve it is to set up GitHub Checks powered by UndercoverCI. Every warning will be delivered as a check annotation, right in the diff, alongside a summary of all changed classes, blocks and methods, decorated with coverage data.
While reading these is a timely conversation starter for you and your reviewers to decide if the testing quality and meets your standards, the agents can take over smoothly as well. The below prompt is all you need, given your agent can access an authorized gh CLI.
Address undercover feedback from https://github.com/grodowski/undercover-ci/pull/809
This gets us from:
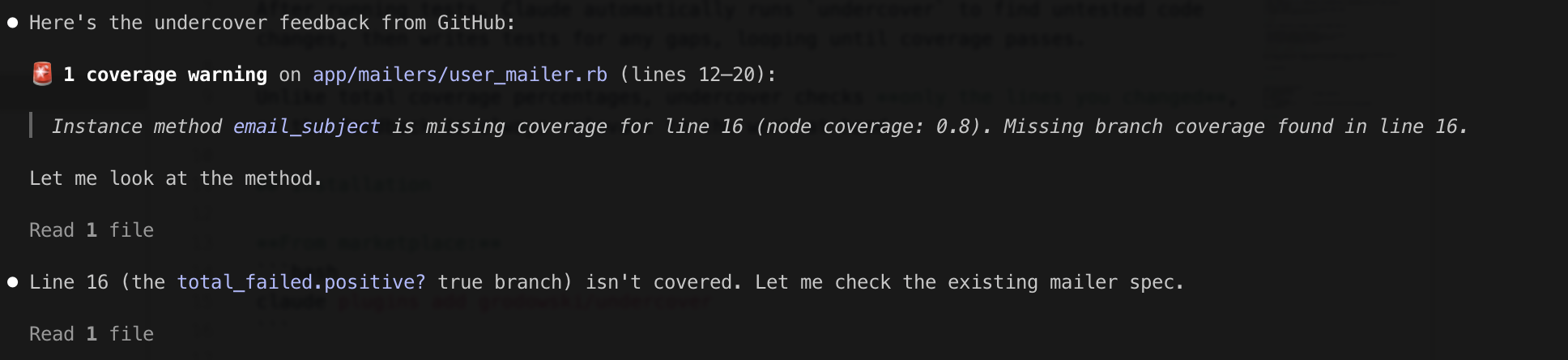
To:

✨
That's the full loop, from a local and timely coverage check to a team-wide enforcement with Undercover CI. Want to set it up for your team? Reach out at [email protected] or just get started here.